Announcing the Release of Apache Flink 1.18
October 24, 2023 - Jing Ge (@jingengineer) Konstantin Knauf (@snntrable) Sergey Nuyanzin (@uckamello) Qingsheng Ren (@renqstuite)The Apache Flink PMC is pleased to announce the release of Apache Flink 1.18.0. As usual, we are looking at a packed release with a wide variety of improvements and new features. Overall, 174 people contributed to this release completing 18 FLIPS and 700+ issues. Thank you!
Let’s dive into the highlights.
Towards a Streaming Lakehouse #
Flink SQL Improvements #
Introduce Flink JDBC Driver For SQL Gateway #
Flink 1.18 comes with a JDBC Driver for the Flink SQL Gateway. So, you can now use any SQL Client that supports JDBC to interact with your tables via Flink SQL. Here is an example using SQLLine.
sqlline> !connect jdbc:flink://localhost:8083
sqlline version 1.12.0
sqlline> !connect jdbc:flink://localhost:8083
Enter username for jdbc:flink://localhost:8083:
Enter password for jdbc:flink://localhost:8083:
0: jdbc:flink://localhost:8083> CREATE TABLE T(
. . . . . . . . . . . . . . .)> a INT,
. . . . . . . . . . . . . . .)> b VARCHAR(10)
. . . . . . . . . . . . . . .)> ) WITH (
. . . . . . . . . . . . . . .)> 'connector' = 'filesystem',
. . . . . . . . . . . . . . .)> 'path' = 'file:///tmp/T.csv',
. . . . . . . . . . . . . . .)> 'format' = 'csv'
. . . . . . . . . . . . . . .)> );
No rows affected (0.122 seconds)
0: jdbc:flink://localhost:8083> INSERT INTO T VALUES (1, 'Hi'), (2, 'Hello');
+----------------------------------+
| job id |
+----------------------------------+
| fbade1ab4450fc57ebd5269fdf60dcfd |
+----------------------------------+
1 row selected (1.282 seconds)
0: jdbc:flink://localhost:8083> SELECT * FROM T;
+---+-------+
| a | b |
+---+-------+
| 1 | Hi |
| 2 | Hello |
+---+-------+
2 rows selected (1.955 seconds)
0: jdbc:flink://localhost:8083>
More Information
Stored Procedure Support for Flink Connectors #
Stored procedures have been an indispensable tool in traditional databases, offering a convenient way to encapsulate complex logic for data manipulation and administrative tasks. They also offer the potential for enhanced performance, since they can trigger the handling of data operations directly within an external database. Other popular data systems like Trino and Iceberg automate and simplify common maintenance tasks into small sets of procedures, which greatly reduces users’ administrative burden.
This new update primarily targets developers of Flink connectors, who can now
predefine custom stored procedures into connectors via the Catalog interface.
The primary benefit to users is that connector-specific tasks that previously
may have required writing custom Flink code can now be replaced with simple
calls that encapsulate, standardize, and potentially optimize the underlying
operations. Users can execute procedures using the familiar CALL syntax, and
discover a connector’s available procedures with SHOW PROCEDURES. Stored
procedures within connectors improves the extensibility of Flink’s SQL and
Table APIs, and should unlock smoother data access and management for users.
Users can use CALL to directly call built-in stored procedures provided by their catalog. For the built-in
stored procedures in catalog, please refer to the documentation of the corresponding catalog. For example, when using
the Apache Paimon catalog, you can use a stored procedure to trigger compaction for a table.
CREATE TABLE `paimon`.`default`.`T` (
id BIGINT PRIMARY KEY NOT ENFORCED,
dt STRING, -- format 'yyyy-MM-dd'
v STRING
);
-- use catalog before call procedures
USE CATALOG `paimon`;
-- compact the whole table using call statement
CALL sys.compact('default.T');
More Information
Extended DDL Support #
From this release onwards, Flink supports
REPLACE TABLE AS SELECTCREATE OR REPLACE TABLE AS SELECT
and both these commands and previously supported CREATE TABLE AS can now support atomicity provided the underlying
connector also supports this.
Moreover, Apache Flink now supports TRUNCATE TABLE in batch execution mode. Same as before, the underlying connector needs to implement and provide this capability
And, finally, we have also implemented support for adding, dropping and listing partitions via
ALTER TABLE ADD PARTITIONALTER TABLE DROP PARTITIONSHOW PARTITIONS
More Information
- Documentation on TRUNCATE
- Documentation on CREATE OR REPLACE
- Documentation on ALTER TABLE
- FLIP-302: Support TRUNCATE TABLE statement in batch mode
- FLIP-303: Support REPLACE TABLE AS SELECT statement
- FLIP-305: Support atomic for CREATE TABLE AS SELECT(CTAS) statement
Time Traveling #
Flink supports the time travel SQL syntax for querying historical versions of data that allows users to specify a point in time and retrieve the data and schema of a table as it appeared at that time. With time travel, users can easily analyze and compare historical versions of data.
For example, a user can query a table at a specified point in time with the following statement;
-- Query the table `tb` for data on November 11, 2022
SELECT * FROM tb FOR SYSTEM_TIME AS OF TIMESTAMP '2022-11-11 00:00:00';
More information
Streaming Execution Improvements #
Support Operator-Level State TTL in Table API & SQL #
Starting from Flink 1.18, Table API and SQL users can set state time-to-live (TTL) individually for stateful operators.
This means that for scenarios like stream regular joins, users can now set different TTLs for the left and right
streams. In previous versions, state expiration could only be controlled at the pipeline level using the configuration
table.exec.state.ttl. With the introduction of operator-level state retention, users can now optimize resource
usage according to their specific requirements.
More Information
Watermark Alignment and Idleness Detection in SQL #
You can now configure watermark alignment and source idleness timeouts in pure SQL via hints. Previously, these features were only available in the DataStream API.
More Information
Batch Execution Improvements #
Hybrid Shuffle supports Remote Storage #
Hybrid Shuffle supports storing the shuffle data in remote storage. The remote storage path can be configured with the
option taskmanager.network.hybrid-shuffle.remote.path. Hybrid Shuffle uses less network memory than before by
decoupling the memory usage from the number of parallelisms, improving the stability and ease of use.
More Information
Performance Improvements & TPC-DS Benchmark #
In previous releases, the community worked extensively to improve Flink’s batch processing performance, which has led to significant improvements. In this release cycle, community contributors continued to put significant effort into further improving Flink’s batch performance.
Runtime Filter for Flink SQL #
Runtime filter is a common method for optimizing Join performance. It is designed to dynamically generate filter conditions for certain Join queries at runtime to reduce the amount of scanned or shuffled data, avoid unnecessary I/O and network transmission, and speed up the query. We introduced runtime filters in Flink 1.18, and verified its effectiveness through the TPC-DS benchmark, and observed up to 3x speedup for some queries by enabling this feature.
Operator Fusion Codegen for Flink SQL #
Operator Fusion Codegen improves the execution performance of a query by fusing an operator DAG into a single optimized operator that eliminates virtual function calls, leverages CPU registers for intermediate data and reduces the instruction cache miss. As a general technical optimization, we verified its effectiveness through TPC-DS, and only some batch operators (Calc, HashAgg, and HashJoin) completed fusion codegen support in version 1.18, getting significant performance gains on some query.
Note that both features are disabled by default in Flink 1.18 and the Community is looking for feedback by users before
enabling them by default. They can be enabled by using table.optimizer.runtime-filter.enabled and
table.exec.operator-fusion-codegen.enabled respectively.
Since Flink 1.16, the Apache Flink Community has been continuously tracking the performance of its batch engine via the TPC-DS benchmarking framework. After significant improvements in Flink 1.17 (dynamic join-reordering, dynamic local aggregations), the two improvements described in the previous sections (operator fusion, runtime filters) lead to 14% performance improvement compared to Flink 1.17, a 54% performance improvement compared to Flink 1.16 on a 10T dataset for partitioned tables.
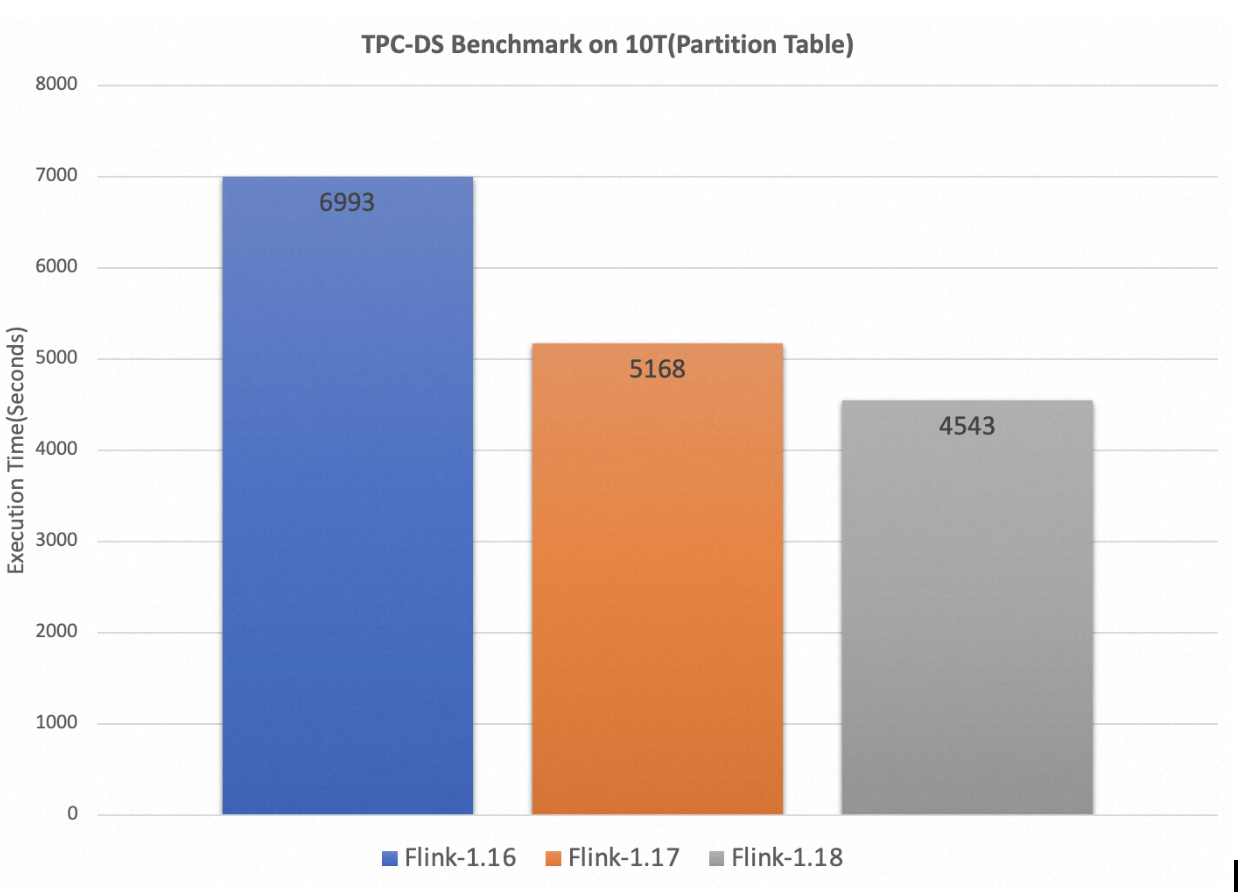
More Information
- FLIP-324: Introduce Runtime Filter for Flink Batch Jobs
- FLIP-315: Support Operator Fusion Codegen for Flink SQL
- Benchmarking repository
Towards Cloud-Native Elasticity #
Elasticity describes the ability of a system to adapt to workload changes in a non-disruptive, ideally automatic manner. It is a defining characteristic of cloud-native systems and for long-running streaming workloads it is particularly important. As such, elasticity improvements are an area of continuous investment in the Apache Flink community. Recent initiatives include the Kubernetes Autoscaler, numerous improvements to rescaling performance and last but not least the Adaptive Scheduler.
The Adaptive Scheduler was first introduced in Flink 1.15 and constitutes a centerpiece of a fully-elastic Apache Flink deployment. At its core, it allows jobs to change their resource requirements and parallelism during runtime. In addition, it also adapts to the available resources in the cluster by only rescaling once the cluster can satisfy the minimum required resources of the job.
Until Flink 1.18, the adaptive scheduler was primarily used in Reactive Mode, which meant that a single job by design would always use all the available resources in the cluster. Please see this blog post on how to autoscale Flink Jobs in Reactive Mode using a Horizontal Pod Autoscaler on Kubernetes.
With Flink 1.18 the adaptive scheduler becomes much more powerful and more widely applicable and is on a trajectory to becoming the default scheduler for streaming workloads on Apache Flink.
Dynamic Fine-Grained Rescaling via REST API #
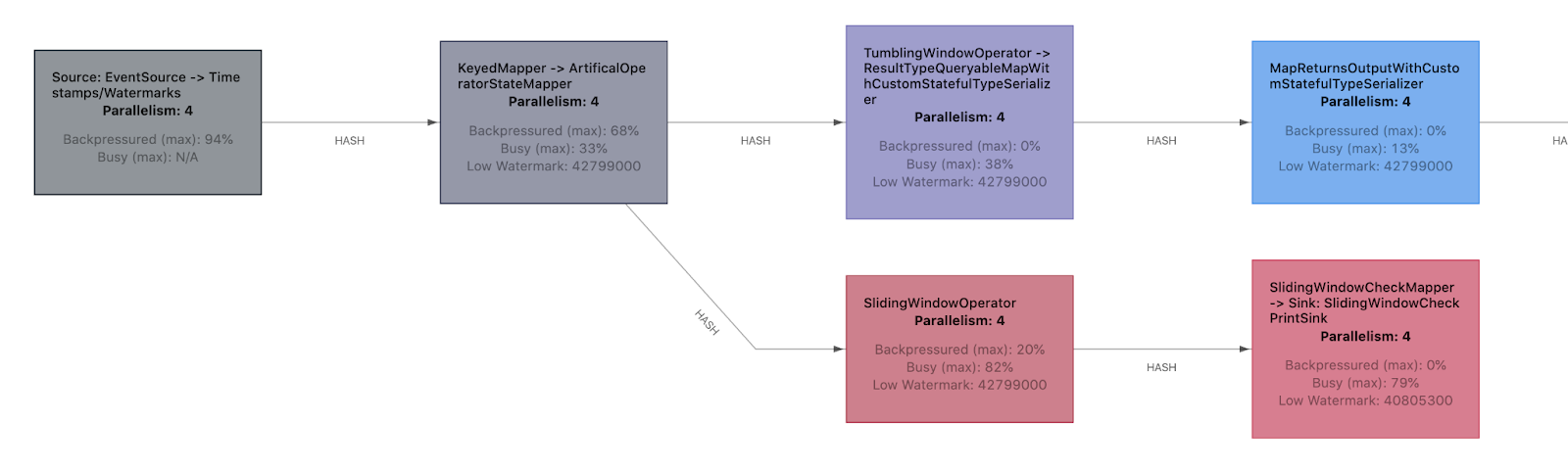
Despite the underlying capabilities of the Adaptive Scheduler, the ability to change the resource requirements of a Job during runtime has not yet been exposed to the end user directly. This changes in Flink 1.18. You can now change the parallelism of any individual task of your job via the Flink Web UI and REST API while the job is running.
Under the hood, Apache Flink performs a regular rescaling operation as soon as the required resources for the new parallelism have been acquired. The rescaling operation is not based on a Savepoint, but on an ordinary, periodic checkpoint, which means it does not introduce any additional snapshot. As you can see in the video above, the rescaling operation already happens nearly instantaneously and with a very short downtime for jobs with small state size.
In conjunction with the backpressure monitor of the Apache Flink Web UI, it is now easier than ever to find and maintain an efficient, backpressure-free parallelism for each of the tasks:
- If a task is very busy (red), you increase the parallelism.
- If a task is mostly idle (blue), you decrease the parallelism.
More Information
Faster Rescaling with RocksDB #
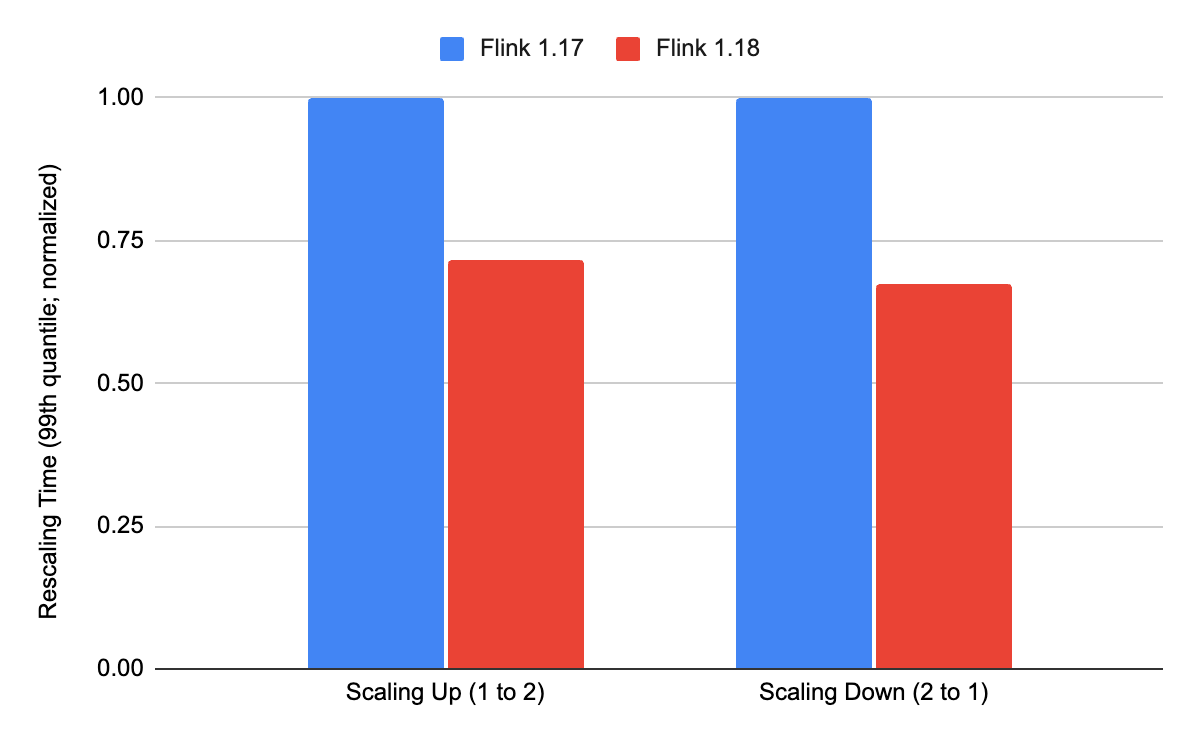
The rescaling times when using RocksDB Statebackend with incremental checkpoints have been improved about 30% in the 99th quantile.
We increased the potential for parallel download from just downloading state handles in parallel to downloading individual files in parallel.
Furthermore, we deactivated write-ahead-logging for batch-inserting into the temporary RocksDB instances we use for rescaling.
More Information
Support for Java 17 #
Java 17 was released in 2021 and is the latest long-term support (LTS) release of Java with an end-of-life in 2029. So, it was about time that Apache Flink added support for it. What does this mean concretely? As of Flink 1.18, you can now run Apache Flink on Java 17 and the official Docker repository includes an image based on Java 17.
docker pull flink:1.18.0-java17
If your cluster runs on Java 17, this of course, also allows you to use Java 17 features in your user programs and to compile it to a target version of Java 17.
More Information
Others Improvements #
Production-Ready Watermark Alignment #
Supported as “Beta” since Flink 1.16 and Flink 1.17, watermark alignment has been thoroughly tested at scale in the real world. Over that time the community has collected and addressed bugs and performance issues as they were discovered. With the resolution of these issues, we are now happy to recommend watermark alignment for general use.
More Information
Pluggable Failure Handling #
Apache Flink serves as the foundation for numerous stream processing platforms at companies like Apple, Netflix or Uber. It is also the basis for various commercial stream processing services. Therefore, its ability to easily integrate into the wider ecosystem of these internal as well as vendor platforms becomes increasingly important. The catalog modification listener and pluggable failure handlers fall into this category of improvements.
More Information
SQL Client Quality of Life Improvements #
In 1.18 the SQL Client received a collection of usability improvements:
- The SQL Client is now more colorful with the ability to enable SQL syntax highlighting and switching among 7 different color schemes
- It is now easier to edit and navigate through very large queries.
- It is now possible to turn line numbers off and on.
More Information
Apache Pekko instead of Akka #
A year ago, Lightbend announced changing the license of future versions of Akka (2.7+) from Apache 2.0 to BSL. It was also announced that Akka 2.6, the version that Apache Flink uses, would receive security updates and critical bug fixes until September of 2023. As September 2023 was approaching, we decided to switch from Akka to Apache Pekko (incubating). Apache Pekko (incubating) is a fork of Akka 2.6.x, prior to the Akka project’s adoption of the Business Source License. Pekko recently released Apache Pekko 1.0.1-incubating, which enabled us to already use it in Flink 1.18 - just in time. While our mid-term plan is to drop the dependency on Akka or Pekko altogether (see FLINK-29281), the switch to Pekko presents a good short-term solution and ensures that the Apache Pekko and Apache Flink Community can address critical bug fixes and security vulnerabilities throughout our software supply chain.
More Information
Calcite Upgrade(s) #
In Apache Flink 1.18, Apache Calcite was gradually upgraded from 1.29 to 1.32. The immediate benefit of these upgrades
are bug fixes, a smarter optimizer and performance improvements. On a parser level, it now allows joins to be
grouped into trees using parentheses (mentioned in SQL-92) e.g. SELECT * FROM a JOIN (b JOIN c ON b.x = c.x) ON a.y = c.y
also see CALCITE-35. In addition, the upgrade to Calcite 1.31+ has
unblocked the support of Session Windows via Table-Valued Functions (see
CALCITE-4865,
FLINK-24024) and as a corollary the deprecation of the legacy
group window aggregations.
Due to CALCITE-4861 Flink’s casting behavior has slightly changed.
Some corner cases might behave differently now: For example, casting from FLOAT/DOUBLE 9234567891.12 to INT/BIGINT has
now Java behavior for overflows.
More Information
Important Deprecations #
In preparation for the release of Flink 2.0 next year, the community has decided to officially deprecate multiple APIs that were approaching end of life for a while.
SourceFunctionis now officially deprecated and will be dropped in Flink 2.0. If you are still using a connector that is built on top ofSourceFunctionplease migrate it toSource.SinkFunctionis not officially deprecated, but it is also approaching end-of-life and will be superseded bySinkV2.- Queryable State is now officially deprecated and will be dropped in Flink 2.0.
- The DataSet API is now
officially deprecated. Users are recommended to migrate to the DataStream API with
execution mode
BATCH.
Upgrade Notes #
The Flink community tries to ensure that upgrades are as seamless as possible. However, certain changes may require users to make adjustments to certain parts of the program when upgrading to version 1.18. Please refer to the release notes for a comprehensive list of adjustments to make and issues to check during the upgrading process.
List of Contributors #
The Apache Flink community would like to express gratitude to all the contributors who made this release possible:
Aitozi, Akinfolami Akin-Alamu, Alain Brown, Aleksandr Pilipenko, Alexander Fedulov, Anton Kalashnikov, Archit Goyal, Bangui Dunn, Benchao Li, BoYiZhang, Chesnay Schepler, Chris Nauroth, Colten Pilgreen, Danny Cranmer, David Christle, David Moravek, Dawid Wysakowicz, Deepyaman Datta, Dian Fu, Dian Qi, Dong Lin, Eric Xiao, Etienne Chauchot, Feng Jin, Ferenc Csaky, Fruzsina Nagy, Gabor Somogyi, Gunnar Morling, Gyula Fora, HaiYang Chen, Hang Ruan, Hangxiang Yu, Hanyu Zheng, Hong Liang Teoh, Hongshun Wang, Huston, Jacky Lau, James Hughes, Jane Chan, Jark Wu, Jayadeep Jayaraman, Jia Liu, JiangXin, Joao Boto, Junrui Lee, Juntao Hu, K.I. (Dennis) Jung, Kaiqi Dong, L, Leomax_Sun, Leonard Xu, Licho, Lijie Wang, Liu Jiangang, Lyn Zhang, Maomao Min, Martijn Visser, Marton Balassi, Mason Chen, Matthew de Detrich, Matthias Pohl, Min, Mingliang Liu, Mohsen Rezaei, Mrart, Mulavar, Nicholas Jiang, Nicolas Fraison, Noah, Panagiotis Garefalakis, Patrick Lucas, Paul Lin, Peter Vary, Piotr Nowojski, Qingsheng Ren, Ran Tao, Rich Bowen, Robert Metzger, Roc Marshal, Roman Khachatryan, Ron, Rui Fan, Ryan Skraba, Samrat002, Sergey Nuyanzin, Sergio Morales, Shammon FY, ShammonFY, Shengkai, Shuiqiang Chen, Stefan Richter, Tartarus0zm, Timo Walther, Tzu-Li (Gordon) Tai, Venkata krishnan Sowrirajan, Wang FeiFan, Weihua Hu, Weijie Guo, Wencong Liu, Xiaogang Zhou, Xintong Song, XuShuai, Yanfei Lei, Yu Chen, Yubin Li, Yun Gao, Yun Tang, Yuxin Tan, Zakelly, Zhanghao Chen, ZhengYiWeng, Zhu Zhu, archzi, baiwuchang, cailiuyang, chenyuzhi, darenwkt, dongwoo kim, eason.qin, felixzh, fengli, frankeshi, fredia, godfrey he, haishui, hehuiyuan, huangxingbo, jiangxin, jiaoqingbo, jinfeng, jingge, kevin.cyj, kristoffSC, leixin, leiyanfei, liming.1018, lincoln lee, lincoln.lil, liujiangang, liuyongvs, luoyuxia, maigeiye, mas-chen, novakov-alexey, oleksandr.nitavskyi, pegasas, sammieliu, shammon, shammon FY, shuiqiangchen, slfan1989, sunxia, tison, tsreaper, wangfeifan, wangkang, whjshj, wuqqq, xiangyu0xf, xincheng.ljr, xmzhou, xuyu, xzw, yuanweining, yuchengxin, yunfengzhou-hub, yunhong, yuxia Luo, yuxiqian, zekai-li, zhangmang, zhengyunhong.zyh, zzzzzzzs, 沈嘉琦