Exploring the thread mode in PyFlink
May 6, 2022 - Xingbo Huang Dian FuPyFlink was introduced in Flink 1.9 which purpose is to bring the power of Flink to Python users and allow Python users to develop Flink jobs in Python language. The functionality becomes more and more mature through the development in the past releases.
Before Flink 1.15, Python user-defined functions will be executed in separate Python processes (based on the Apache Beam Portability Framework). It will bring additional serialization/deserialization overhead and also communication overhead. In scenarios where the data size is big, e.g. image processing, etc, this overhead becomes non-negligible. Besides, since it involves inter-process communication, the processing latency is also non-negligible, which is unacceptable in scenarios where the latency is critical, e.g. quantitative transaction, etc.
In Flink 1.15, we have introduced a new execution mode named ’thread’ mode (based on PEMJA) where the Python user-defined functions will be executed in the JVM as a thread instead of a separate Python process. In this article, we will dig into the details about this execution mode and also share some benchmark data to give users a basic understanding of how it works and which scenarios it’s applicable for.
Process Mode #

Fig. 1 - PyFlink Architecture Overview
From Fig. 1, we can see the architecture of PyFlink. As shown on the left side of Fig.1, users could use PyFlink API(Python Table API & SQL or Python DataStream API) to declare the logic of jobs, which will be finally translated into JobGraph (DAG of the job) which could be recognized by Flink’s execution framework. It should be noted that Python operators (Flink operators whose purpose is to execute Python user-defined functions) will be used to execute the Python user-defined functions.
On the right side of Fig. 1, it shows the details of the Python operators where the Python user-defined functions were executed in separate Python processes.
In order to communicate with the Python worker process, a series of communication services are required between the Python operator(runs in JVM) and the Python worker(runs in Python VM). PyFlink has employed Apache Beam Portability framework to execute Python user-defined functions which provides the basic building blocks required for PyFlink.
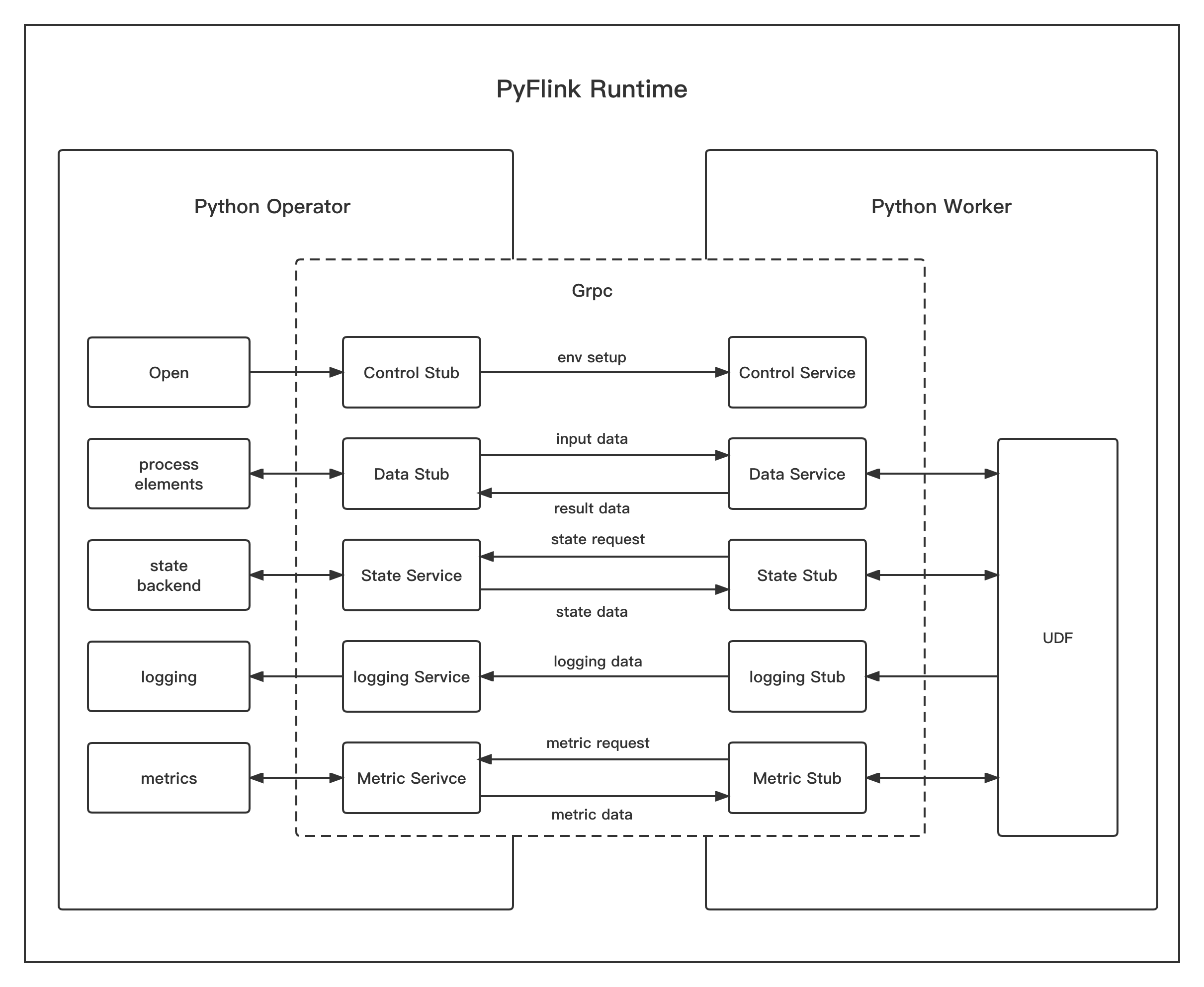
Fig. 2 - PyFlink Runtime in Process Mode
Process mode can be executed stably and efficiently in most scenarios. It is enough for more users. However, in some scenarios, it doesn’t work well due to the additional serialization/deserialization overhead. One of the most typical scenarios is image processing, where the input data size is often very big. Besides, since it involves inter-process communication, the processing latency is also non-negligible which is unacceptable in scenarios where latency is critical, e.g. quantitative transaction, etc. In order to overcome these problems, we have introduced a new execution mode(thread mode) where Python user-defined functions will be executed in the JVM as a thread instead of a separate Python process. In the following section, we will dig into the details of this new execution mode.
PEMJA #
Before digging into the thread mode, let’s introduce a library PEMJA firstly, which is the core to the architecture of thread mode.
As we all know, Java Native Interface (JNI) is a standard programming interface for writing Java native methods and embedding the Java virtual machine into native applications. What’s more, CPython provides Python/C API to help embed Python in C Applications.
So if we combine these two interfaces together, we can embed Python in Java Application. Since this library solves a general problem that Python and Java could call each other, we have open sourced it as an independent project, and PyFlink has depended on PEMJA since Flink 1.15 to support thread mode.
PEMJA Architecture #
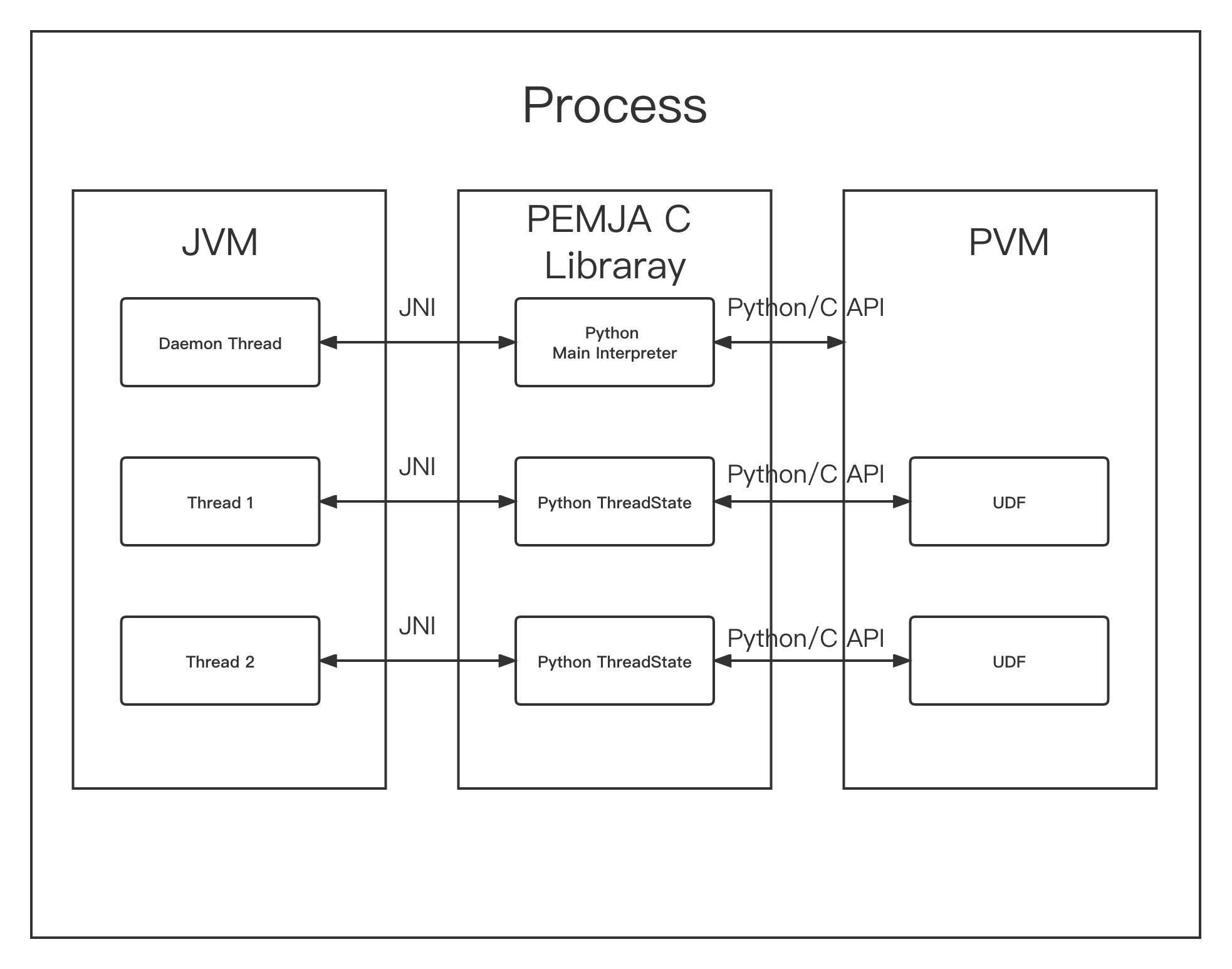
Fig. 3 - PEMJA Architecture
As we can see from the architecture of PEMJA in Fig. 3, JVM and PVM can call each other in the same process through PEMJA Library.
Firstly, PEMJA will start a daemon thread in JVM, which is responsible for initializing the Python Environment and creating a Python Main Interpreter owned by this process. The reason why PEMJA uses a dedicated thread to initialize Python Environment is to avoid potential deadlocks in Python Interpreter. Python Interpreter could deadlock when trying to acquire the GIL through methods such as PyGILState_* in Python/C API concurrently. It should be noted that PEMJA doesn’t call those methods directly, however, it may happen that third-party libraries may call them, e.g. numpy, etc. To get around this, we use a dedicated thread to initialize the Python Environment.
Then, each Java worker thread can invoke the Python functions through the Python ThreadState created from Python Main Interpreter.
Comparison with other solutions #
| Framework | Principle | Limitations |
|---|---|---|
| Jython | Python compiler implemented in Java |
|
| GraalVM | Truffle framework |
|
| JPype | JNI + Python/C API |
|
| Jep | JNI + Python/C API |
|
| PEMJA | JNI + Python/C API |
|
In the table above, we have made a basic comparison of the popular solutions of Java/Python calling libraries.
Jython: Jython is a Python interpreter implemented in Java language. Because its implementation language is Java, the interoperability between code implemented by Python syntax and Java code will be very natural. However, Jython does not support Python 3 anymore, and it is no longer actively maintained.
GraalVM: GraalVM takes use of Truffle framework to support interoperability between Python and Java. However, it has the limitation that not all the Python libraries are supported. As we know, many Python libraries rely on standard CPython to implement their C extensions. The other problem is that it only works with GraalVM, which means high migration costs.
JPype: Similar to PEMJA, JPype is also a framework built using JNI and Python/C API, but JPype only supports calling Java from Python.
Jep: Similar to PEMJA, Jep is also a framework built using JNI and Python/C API and it supports calling Python from Java. However, it doesn’t provide a jar to the maven repository and the process of loading native packages needs to be specified in advance through jvm parameters or environment variables when the JVM starts, which makes it difficult to integrate. Furthermore, our benchmark shows that the performance is not very good.
PEMJA: Similar to Jep and JPype, PEMJA is built on CPython, so it cannot support other Python interpreters, such as PyPy, etc. Since CPython is the most used implementation and standard of Python Runtime officially provided by Python, most libraries of the Python ecology are built on CPython Runtime and so could work with PEMJA naturally.
Thread Mode #
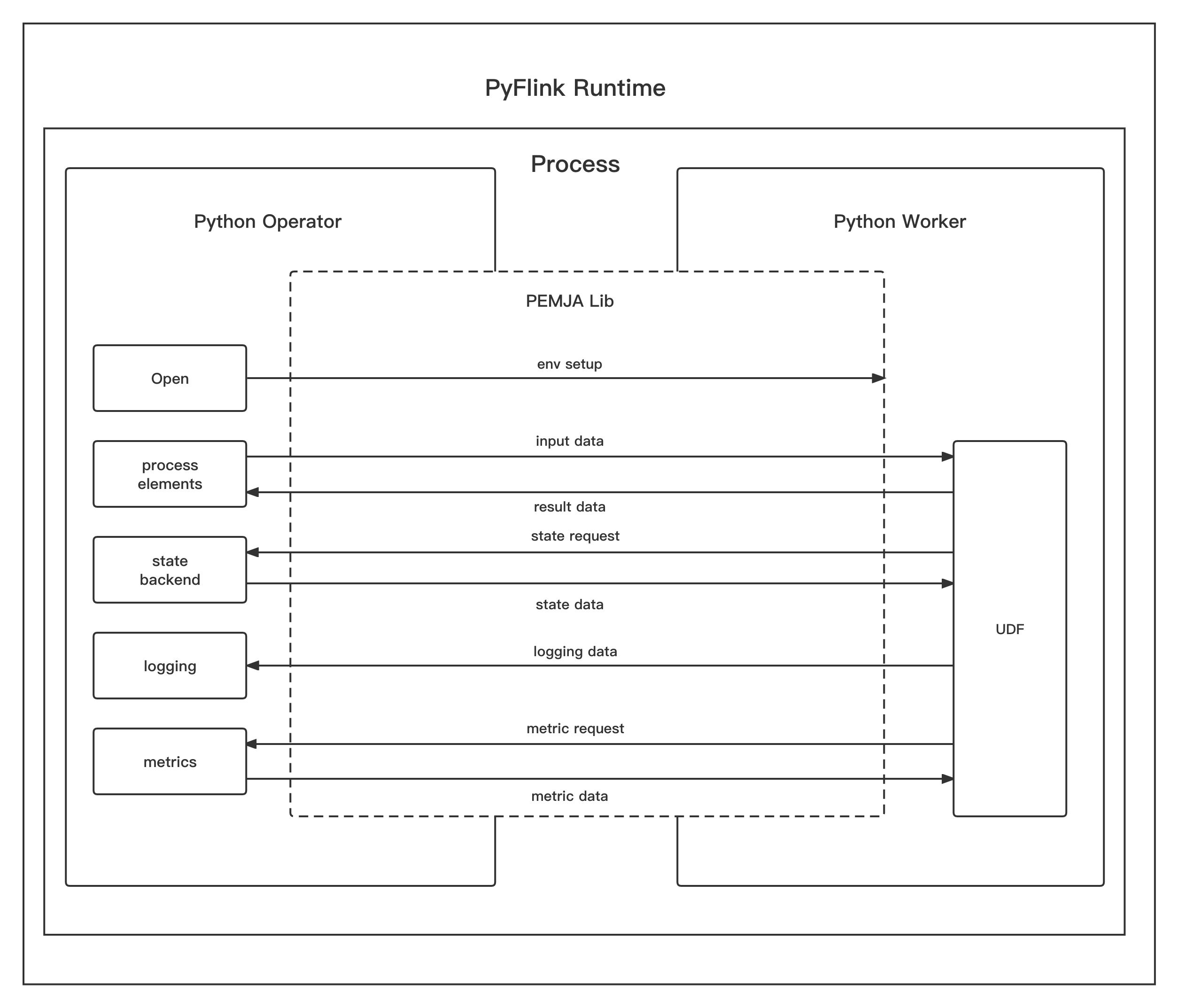
Fig. 4 - PyFlink Runtime in Thread Mode
From the picture above, we can see that in thread mode, the Python user-defined function runs in the same process as the Python operator(which runs in JVM). PEMJA is used as a bridge between the Java code and the Python code.
Since the Python user-defined function runs in JVM, for each input data received from the upstream operators, it will be passed to
the Python user-defined function directly instead of buffered and passed to the Python user-defined function in a batch.
Therefore, thread mode could have lower latency compared to the process mode. Currently, if users want to achieve lower latency in process mode, usually they need to configure the
python.fn-execution.bundle.size or python.fn-execution.bundle.time to a lower value. However, since it involves inter-process communication,
the latency is still a little high in some scenarios. However, this is not a problem any more in thread mode. Besides, configuring python.fn-execution.bundle.size or python.fn-execution.bundle.time to
a lower value usually will affect the overall performance of the job and this will also not be a problem in thread mode.
Comparisons between process mode and thread mode #
| Execution Mode | Benefits | Limitations |
|---|---|---|
| Process Mode |
|
|
| Thread Mode |
|
|
Benefits of thread mode #
Since it processes data in batches in process mode, currently Python user-defined functions could not be used in some scenarios, e.g. used in the Join(Table API & SQL) condition and taking columns both from the left table and the right table as inputs. However, this will not be a big problem any more in thread mode because of the nature that it handles the data one by one instead of a batch.
Unlike process mode which sends and receives data asynchronously in batches, in thread mode, data will be processed synchronously one by one. So usually it will have lower latency and also less checkpoint time. In terms of performance, since there is no inter-process communication, it could avoid data serialization/deserialization and communication overhead, as well as the stage of copying and context switching between kernel space and user space, so it usually will have better performance in thread mode.
Limitations #
However, there are also some limitations for thread mode:
- It only supports CPython which is also one of the most used Python interpreters.
- It doesn’t support session mode well and so it’s recommended that users only use thread mode in per-job or application deployments. The reason is it doesn’t support using different Python interpreters for the jobs running in the same TaskManager. This limitation comes from the fact that many Python libraries assume that they will only be initialized once in the process, so they use a lot of static variables.
Usage #
The execution mode could be configured via the configuration python.execution-mode. It has two possible values:
process: The Python user-defined functions will be executed in a separate Python process. (default)thread: The Python user-defined functions will be executed in the same process as Java operators.
For example, you could configure it as following in Python Table API:
# Specify `process` mode
table_env.get_config().set("python.execution-mode", "process")
# Specify `thread` mode
table_env.get_config().set("python.execution-mode", "thread")
It should be noted that since this is still the first release of ’thread’ mode, currently there are still many limitations about it, e.g. it only supports Python ScalarFunction of Python Table API & SQL. It will fall back to ‘process’ mode where ’thread’ mode is not supported. So it may happen that you configure a job to execute in thread mode, however, it’s actually executed in ‘process’ execution mode.
Benchmark #
Test environment #
OS: Alibaba Cloud Linux (Aliyun Linux) release 2.1903 LTS (Hunting Beagle)
CPU: Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz
Memory: 16G
CPython: Python 3.7.3
JDK: OpenJDK Runtime Environment (build 1.8.0_292-b10)
PyFlink: 1.15.0
Test results #
Here, we test the json processing which is a very common scenario for PyFlink users.
The UDF implementation is as following:
# python udf
@udf(result_type=DataTypes.STRING(), func_type="general")
def json_value_lower(s: str):
import json
a = json.loads(s)
a['a'] = a['a'].lower()
return json.dumps(a)
// Java UDF
public class JsonValueLower extends ScalarFunction {
private transient ObjectMapper mapper;
private transient ObjectWriter writer;
@Override
public void open(FunctionContext context) throws Exception {
this.mapper = new ObjectMapper();
this.writer = mapper.writerWithDefaultPrettyPrinter();
}
public String eval(String s) {
try {
StringObject object = mapper.readValue(s, StringObject.class);
object.setA(object.a.toLowerCase());
return writer.writeValueAsString(object);
} catch (JsonProcessingException e) {
throw new RuntimeException("Failed to read json value", e);
}
}
private static class StringObject {
private String a;
public String getA() {
return a;
}
public void setA(String a) {
this.a = a;
}
@Override
public String toString() {
return "StringObject{" + "a='" + a + '\'' + '}';
}
}
}
The test results is as following:
| Type (input data size) | QPS | Latency | Checkpoint Time |
|---|---|---|---|
| Java UDF (100k) | 900 | 2ms | 100ms |
| Java UDF (10k) | 1w | 20us | 10ms |
| Java UDF (1k) | 5w | 1us | 10ms |
| Java UDF (100) | 28w | 200ns | 10ms |
| Process Mode (100k) | 900 | 5s-10s | 5s |
| Process Mode (10k) | 7000 | 5s-10s | 3s |
| Process Mode (1k) | 3.6w | 3s | 3s |
| Process Mode (100) | 12w | 2s | 2s |
| Thread Mode (100k) | 1200 | 1ms | 100ms |
| Thread Mode (10k) | 1.2w | 20us | 10ms |
| Thread Mode (1k) | 5w | 3us | 10ms |
| Thread Mode (100) | 12w | 1us | 10ms |
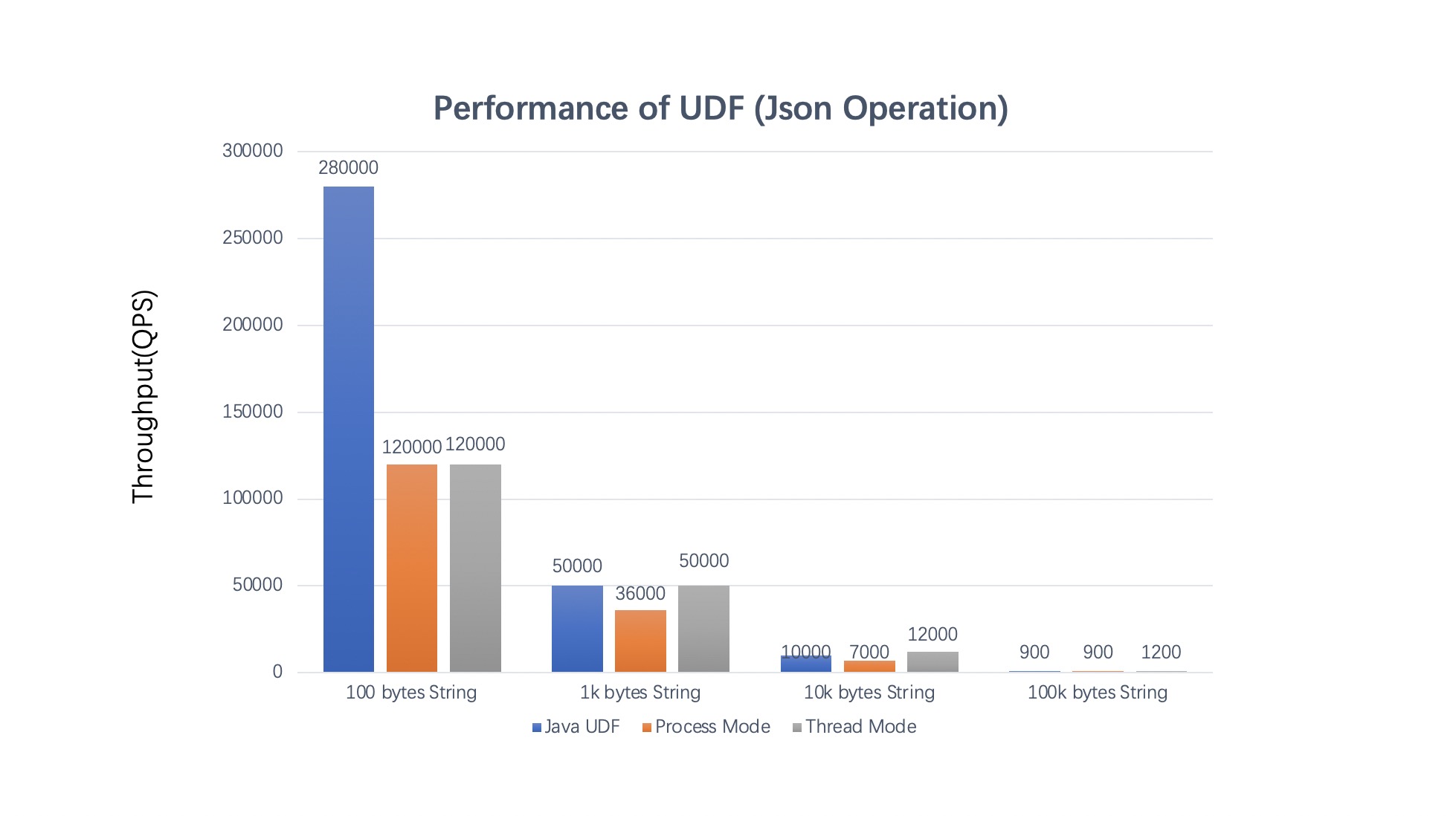
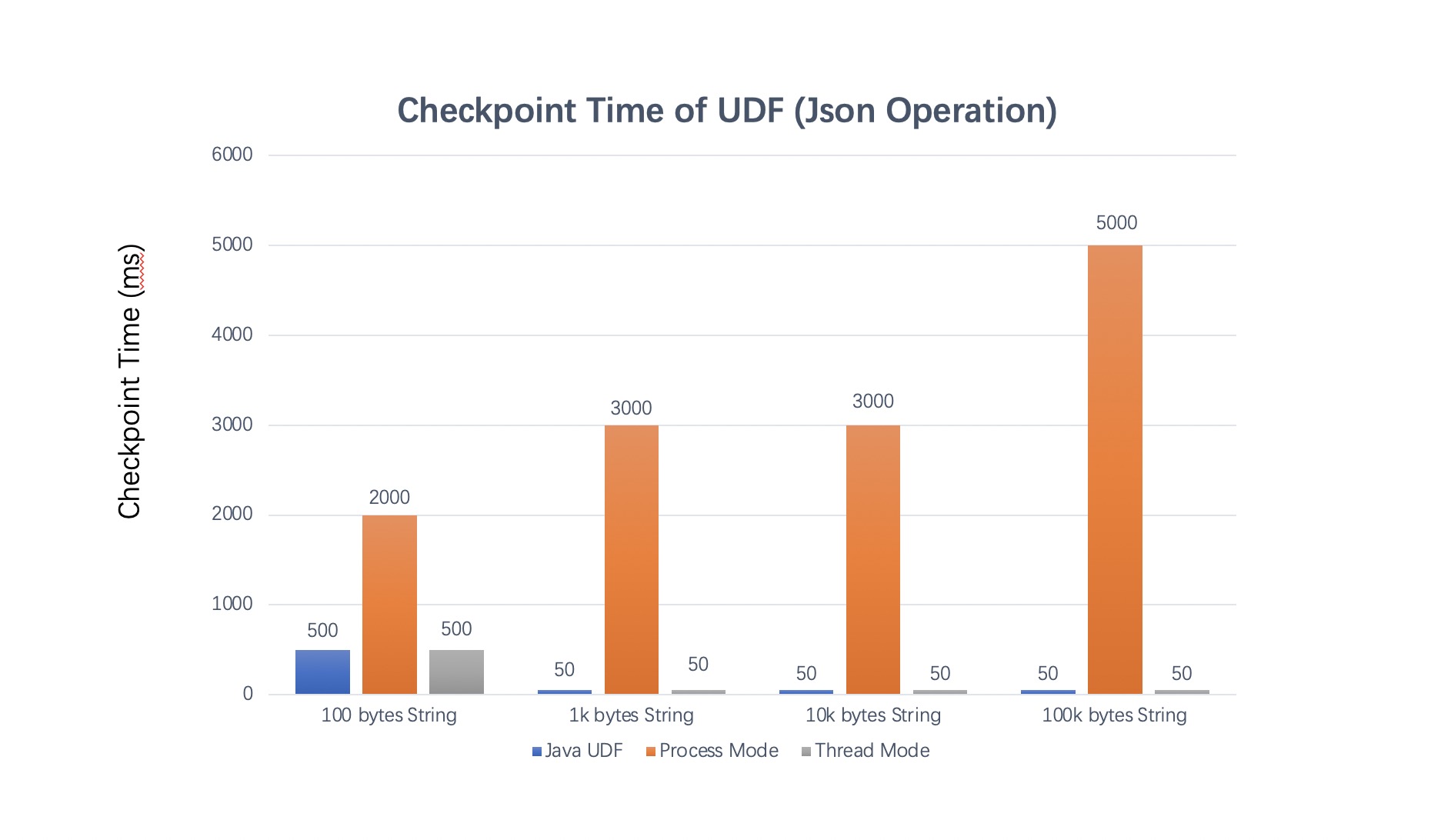
As we can see from the test results:
-
If you care about latency and checkpoint time, thread mode is your better choice. The processing latency could be decreased from several seconds in process mode to microseconds in thread mode.
-
Thread mode can bring better performance than process mode when data serialization/deserialization is not negligible relative to UDF calculation itself. Compared to process mode, benchmark has shown that the throughput could be increased by 2x in common scenarios such as json processing in thread mode. However, if the UDF calculation is slow and spends much longer time, then it is more recommended to use process mode, because the process mode is more mature and it has better resource isolation.
-
When the performance of Python UDF is close to that of Java UDF, the end-to-end performance of thread mode will be close to that of Java UDF.
Summary & Future work #
In this article, we have introduced the ’thread’ execution mode in PyFlink which is a new feature introduced in Flink 1.15. Compared with the ‘process’ execution mode, users will get better performance, lower latency, less checkpoint time in ’thread’ mode. However, there are also some limitations about ’thread’ mode, e.g. poor support for session deployment mode, etc.
It should be noted that since this is still the first release of ’thread’ mode, currently there are still many limitations about it, e.g. it only supports Python ScalarFunction of Python Table API & SQL. We’re planning to extend it to other places where Python user-defined functions could be used in next releases.